フロントエンド開発(Vue.js)入門
Vue.jsを使って簡単なアプリを作ってみよう
こちらの記事の目的
現在、私はフィヨルドブートキャンプというプログラミングスクールに在籍しております。Ruby on Railsを扱っており、主にバックエンド開発の学習を対象としていますが、フロントエンド開発のカリキュラムの一環としてVue.jsでTodoアプリを作成するという課題が出されました。こちらはその課題の備忘録となります。
Vue.jsとは何か
フロントエンドの開発に用いられる人気のJavaScriptフレームワークです。その他、代表的なものとしてFacebook社製のReact、Google社が開発したAngularなどが存在します。フレームワーク間の比較等はこの記事では扱いません。
モダンフロントエンドにおけるJSフレームワークの特徴
フレームワークの種類を問わず、現在主流のJSフレームワークの特徴は以下の2つのキーワードで説明できます。
- リアクティブ
- JavaScript側のデータの更新がWebページのDOMツリーに即座に反映される仕組みのこと
- JavaScript側のVueインスタンス内のデータとHTMLを基本としたテンプレート構文に記述した値がバインドされ、データを更新すると、それがすぐにDOMツリーに反映されてWebブラウザの画面が更新される
- DOMとは
- JavaScriptからHTML文書やXML文書の要素を操作する仕組み
- HTML要素をツリー構造として扱うことが可能で、そのツリー構造をDOMツリー、DOMツリーを構成する要素をノードと呼ぶ
- コンポーネントによる開発
- Webサイトの構成要素を複数のパーツに分割して開発するという手法
- コンポーネントを再利用することで効率的に開発が可能
Vue.jsの特徴
Reactなど他のフレームワークを利用したことがないため、難易度などについてはよくわからないのですが、以下のような特徴が挙げられています。
- ユーザーインターフェースを作るライブラリであること
- 利用にあたって、ES6によるプログラミングを強制しないこと
- 初期段階ではNode.js、WebpackやBabelなど初心者にハードルの高い開発ツールの知識が必ずしも必要ないこと
- HTML, CSS, JavaScriptの知識があれば始められるなど、ReactやAngularなどと比較して学習コストが低いこと
そして何よりも、単一ファイルコンポーネントの利用こそVue.jsの最大の特徴と言われています。
Vue.jsではNode.jsやVue CLI 3といった開発環境を導入することにより、単一ファイルコンポーネントと呼ばれるHTML、CSS、JSを1つのファイルにパッケージングしたより柔軟なコンポーネントが利用可能となります。
ただ、単一ファイルコンポーネントの拡張子が.vueのファイルであること、かつES6のモジュール機能を利用しているため、利用するにはNode.jsベースのモジュールハンドラやトランスパイラなどのツールが必要となります。

また、公式ガイドが非常に充実していることも利用するメリットの一つです。日本語で記載されたわかりやすいガイドがあると心強いですよね!
Udemyの日本語動画や関連書籍もどんどん増えてきているので、お薦めです。
Todoアプリ作成に入ろう!
それでは、早速内容に入ります。Todoアプリ作成にはデータバインディングとディレクティブの知識が必須となります。 まず、その前にインストール方法について確認しましょう。
インストール方法
Vue.jsを利用するには、以下の3種類の方法が存在します。
CDNとはWebコンテンツのデリバリーに最適化したネットワークのことです。手軽に利用するにはCDNからVue.jsを読み込むのが最適ですので、こちらの内容で進めます。
また、公式ガイドでは大規模アプリケーションを構築する際にはNPM、大規模なSPA開発にはCLIの利用を推奨しています。それぞれ内容を確認してみて下さい。
CDNによるインストールは驚くほど簡単です。公式ガイドから、以下の内容を抜き出してHTMLのbodyタグの最後に貼るだけです。
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.0"></script>
@2.6.0は最新のバージョン番号のことです。これでVue.jsが使えますね!
データバインディングの基本的な仕組み
記事の前半でリアクティブという言葉に触れました。JavaScript側のデータの更新がDOMツリーに即座に反映される仕組みのことです。 DOMの文書ツリーとJavaScriptのオブジェクトの仲介をするのがJavaScriptフレームワークの役割です。
Vue.jsの場合、Vueインスタンス内のデータとHTMLを基本としたテンプレート構文に記述した値が結び付けられます。 データが変更されても、それがすぐにDOMツリーに反映されるため、ブラウザ上での表示も更新されます。 具体例を見ていきましょう。
# JavaScript(Vueインスタンス)
var app = new Vue({
# オプション指定
el: '#app',
data: {
message: "Hello!!!"
}
})
Vueインスタンスの生成にはnew演算子とVueコンストラクタを使用します。引数はオブジェクトリテラル({キー:値})です。
代表的なオプションは、以下の2つです。
- el(elementの略ですね)
- data
elではVueインスタンスに対応するHTML要素のid属性を指定します。上記の例の場合、idはappです。
dataはVueインスタンスの管理するデータオブジェクトのことです。
# HTMLテンプレート <div id="app"> <p>{{message}}</p> </div>
こちらはHTMLテンプレートです。divタグ内でidが確認できますね。
ただ、見慣れない記号{{}}がありますね。これをMustache構文と呼びます。
この構文が、Vueインスタンスのデータオブジェクト内のmessage変数をバインドしてブラウザに表示します。
ブラウザで確認するとHello!!!と表示されるはずです。
ディレクティブ
データバインディングの基本を確認したので、ディレクティブの内容に入ります。 ディレクティブとはHTMLのタグ内に記述する「v-」で始まる属性のことです。
# HTML <div id="app"> <p><a v-bind:href="toMyBlog">常に初心者</a></p> </div> # JavaScript var app = new Vue({ el: '#app', data: { toMyBlog: 'https://tkm2.hatenablog.com/' } })
上記の場合、HTML属性であるhref属性にリンク先のデータをバインドしています。HTMLの属性にMastache構文は利用できないためです。
因みに、v-bindの部分を省略して、:href=から記載しても構いません。省略記法ですね。
主要ディレクティブ
- v-bind
- HTML属性のバインド
- v-for
- 繰り返し処理
- v-if(v-show)
- 条件分岐
- v-on
- DOMのイベント処理
- v-model
- 双方向データバインディング
v-forによる繰り返し処理
# HTML <div id="app"> <ul> <li v-for="city in cities">{{city}}</li> </ul> </div> # JavaScript new Vue({ el: '#app', data: { cities: ['東京', '大阪', '名古屋'] } });
上記の場合、データオブジェクトのcitiesプロパティに配列を渡し、繰り返し処理を行うことでリストを表示しています。
変数 in 配列名という指定の他、(変数, index) in 配列名などインデックスを表示することも可能です。

v-if/v-showによる条件分岐
v-if="値"の場合、値がtrueの場合などに要素が表示されます。プロパティの値に応じて、要素の表示/非表示を切り替える場合などに用います。
v-ifディレクティブはDOMから要素自体を削除するため、負荷が高くなります。表示/非表示を頻繁に繰り返す場合は、v-showを用いた方が無難です。
v-onによるDOMイベント処理
# HTML <button v-on:click="add(index)" > Delete </button> # JavaScript methods: { add: function(index) { # 処理内容は省略 } } }
上記の例ではv-onというディレクティブを使用してDOMイベントの処理を記述しています。
Deleteボタンをクリックするとadd(index)メソッドが発動します(メソッドはVueインスタンス内で定義しています)。コロン(:)の後にDOMのイベント(click)を記述して、メソッドで処理を指定するという訳です。
v-onもv-bindと同様に省略記法が存在します。v-on:を省略して、頭に@をつけた@clickでOKです。
v-modelによる双方向データバインディング
v-modelはとても面白いディレクティブです。
# HTML <div id="app"> <label for="pets">ペットはいますか?</label> <input id="pets" type="checkbox" v-model="pets" /> {{pets}} </div> # JavaScript new Vue({ el: '#app', data: { pets: false } });
petsプロパティがデフォルトでfalseになっています。チェックボックスにチェックを入れると、falseからtrueに変化するのです。


また、フォームのテキストボックスに文字列を入力すると、インスタンス内のプロパティがバインドされて双方向に値が変化します。
ディレクティブがどう作用するか実際に見てみよう!
<div id="app"> # 省略 <input type="text" v-model="newtask" /> <button class="add" @click="addTask">追加</button> <ul> <li v-for="(todo, index) in todos" > # 省略 </li> </ul> <pre>{{this.todos}}</pre> <pre>{{newtask}}</pre> </div> # JavaScript var app = new Vue({ el: '#app', data: { newtask: '', todos: [] }, methods: { addTask: function() { if (this.newtask == '') return; this.todos.push({ text: this.newtask, done: false, hover: false}); this.newtask = ''; } # 省略
課題のため、全てのコードを記述することはできないですが、ディレクティブがどのように作用しているか確認を行います。
preタグの部分にthis.todosとnewtaskを記述しています。追加ボタンをクリックした後に空配列のtodosがどうなるか、またnewtaskというプロパティがどう変化するか確認しましょう。
テキストエリアに「猫とお散歩」を入力すると(まだボタンはクリックしてません!)・・・

プロパティも猫とお散歩に変化していますね!では、ボタンを押すと・・・

空配列のtodosにオブジェクトがpushされ、リスト表示されていることがわかりますね。また、this.newtask=''により、入力した文字列はクリアされています。
v-modelやv-onが正しく作用しています。
このように複数のディレクティブを組み合わせて、Todoリストを作成します。その他にも以下の内容の機能を追加しました。
ローカルストレージの利用と監視プロパティについて
実装はまだ終わりません。現時点ではリロードした場合、データは消えてしまいます。 DBを使用せずにデータをブラウザに保存してあげましょう。
ブラウザ側でデータをローカルディスクに保存するWebストレージ機能の出番です!HTML5より追加された機能ですね。
Webストレージは以下の2種類に分かれます。
- ローカルストレージ
- セッションストレージ
セッションストレージはセッション単位でデータを保存するため、ブラウザを閉じるとデータが消去されます。
ローカルストレージの場合は、データを永続的にクライアント(Webブラウザ)に保存することが可能です。
ローカルストレージについて
- データをキーと値のペアで保存する
- 文字列の形式でデータを保存する
ローカルストレージにデータを保存する場合は、setItem(キー、値)メソッドを使用します。逆に、ローカルストレージより指定したキーから値を読み込む処理にはgetItem(キー)メソッドを使用します。
キーについては、Vueインスタンスのデータオブジェクト内に追加してあげましょう。
また、JavaScriptのオブジェクトをJSON形式の文字列に変換する場合はJSON.stringify()メソッド、逆の場合はJSON.parse()メソッドを使用してあげると良いですね。
ウォッチャによる監視
では、どのタイミングでローカルストレージにデータを保存してあげればいいのでしょうか。
Vue.jsの場合、watchオプションの「ウォッチャ」機能を使用しましょう。 ウォッチャは特定のプロパティを監視し、データの変化に反応して処理を行います。
watch: {
監視するプロパティ: function() {
// 変化した時に行いたい処理
}
}
ネストした深い階層までデータを監視する場合は、deepオプションをtrueに設定します。
また、Vueインスタンス生成時にストレージに保存したデータを読み込む必要があるため、ライフサイクル関数(ライフサイクルフック)のメソッド(created())を使用しました。
ライフサイクル関数
Vueインスタンスの生成から破棄までのプロセスで自動的に呼びされる関数のことです。
created()の他にも、下記のメソッドが存在します。特定のタイミングに処理を実行したい場合はライフサイクル関数のメソッドを使用してあげると便利です。 ライフサイクル関数はmethodsの外に定義する点にだけ注意しましょう。
- beforeCreate
- created
- beforeMount
- mounted
- beforeUpdate
- updated
- beforeDestroy
- destroyed
ChromeのDeveloperツールで「Application」を選択して確認すると・・・

ローカルストレージにtodosのデータが保存されていることが確認できますね。
最後に
以上で、Vue.jsの入門記事は終了です!
参考文献
多対多の関係について
本記事の内容
フィヨルドブートキャンプでアプリにフォロー機能を実装するという課題がありました。
課題の趣旨として、フォロー機能の核となる多対多の関連付けを正しく実装するという目的があります。
本記事では課題を実装する上で理解するのが難しかったモデルの設計について備忘録としてまとめます。
モデルの関連付けについて
フォロー機能の厄介な点として、フォローするユーザーとフォローされるユーザーが存在することが挙げられます。
このような場合、その関係は1対Nではなく、多対多となります。
1対多の関連付けについては、お馴染みですね。下記のようにhas_manyとbelongs_toを用いて親子関係を表現します。
class Author < ApplicationRecord has_many :books, dependent: :destroy end class Book < ApplicationRecord belongs_to :author end
では、多対多の関係はどのように関連づけるのでしょうか。
まず、フォロー機能実装にあたりFriendshipというモデルを考えます。
これが中間テーブルの役割に該当するのですが、多対多をいきなり考えるとよくわからなくなる(少なくとも私はよくわからなくなりました)ので、まず1対多の関係を考慮します。
1人のユーザーが複数をフォローする場合、つまりフォローする側から考える能動的関係(active_relationship)を考慮します。
能動的関係(active_relationship)
id:1のユーザーが複数をフォローする図式が以下のようになりますね。
| id | 氏名 | |
|---|---|---|
| 1 | 山田太郎 | yamada.tarou@gmail.com |
| follower_id | followed_id |
|---|---|
| 1 | 2 |
| 1 | 10 |
| 8 | 1 |
| 1 | 7 |
| 4 | 1 |
| id | 氏名 | |
|---|---|---|
| 2 | ... | ... |
| id | 氏名 | |
|---|---|---|
| 10 | ... | ... |
| id | 氏名 | |
|---|---|---|
| 7 | ... | ... |
active_relationshipをthrough(通して)、フォローされる側の情報(User.following)を所有する(has_many)というイメージです。
受動的関係(passive_friendship)
次は、フォローされる側(id:1)から見た受動的関係(passive_friendship)です。こちらも1対Nで考えましょう。
これ、先程のFriendshipモデルをひっくり返しただけですよね。
| id | 氏名 | |
|---|---|---|
| 1 | 山田太郎 | yamada.tarou@gmail.com |
| followed_id | follower_id |
|---|---|
| 2 | 1 |
| 10 | 1 |
| 1 | 8 |
| 7 | 1 |
| 1 | 4 |
| id | 氏名 | |
|---|---|---|
| 8 | ... | ... |
| id | 氏名 | |
|---|---|---|
| 4 | ... | ... |
こちらも、passive_relationshipを通して(through)、フォローする側の情報(User.followers)を所有(has_many)するイメージです。
Friendshipという1種類のモデルを、2種類の視点から考慮するのですね。
Friendshipモデル
最後に、Friendshipモデルの関連付けは以下のようになります。
class Friendship < ApplicationRecord belongs_to :follower, class_name: "User" belongs_to :followed, class_name: "User" end
user.rbで定義した外部キーfollowerとfollowedをbelongs_toに記述しています。
問題ないですね。では、実装してみましょう!
実装
まず、User モデルはhas_manyで Friendship モデルを所有しています。
カラムにはどのUserに所有されるかを表す外部キーを持たなくてはなりません。
フォロー機能の場合、フォローする側とフォローされる側という区別が必要ですので、異なる2種類の外部キーが必須となります。
外部キーはフォローする側のfollower_idとフォローされる側のfollowed_idの2種類となります。

いずれも、本来のクラス名はFriendshipなのでclass_name: : "Friendship"というオプションを記載します。
また、ユーザーが削除されたときに自動的にフレンドシップも削除されるようにするため、dependent: :destroy をつけます。
次に、先程のテーブルで確認したようにFriendshipを介してユーザーを取得する処理を考えましょう。

フォローする側のユーザーは、所有するactive_friendshipsを通じてフォローされる側のユーザーfollowedを所有します。
逆に、フォローされる側のUserは、所有するpassive_friendshipsを介してフォローする側のユーザーfollowerを所有します。
sourceはモデルの参照元を明示します。
デフォルトのhas_many throughという関連付けにおいては、Railsはモデルのクラス名 (単数形) に対応する外部キーを探しますが、
今回はsource名に参照先を明示しているお陰で、followed_idやfollower_idから該当ユーザーを取得できます。
source: :followed #フォローされる側 source: :follower #フォローする側
中間テーブルを通して、フォローされる側のユーザーを集めることをfollowing、フォローする側のユーザーを集めることをfollowersと定義しているだけですね。
このhas_many throughの関連付けのお陰で、User.followingやUser.followersでユーザー情報を配列のように取得できます。
# app/models/user.rb def follow(other_user) following << other_user end
上記のメソッドでは、<<演算子を用いてユーザー情報をfollowingnの配列の最後に追記しています。簡単にフォロー機能が実装できますね。
最後に
こちらで記事は終了です。 参考文献:
Railsの学習(アソシエーション編)
ポリモーフィック関連付けを理解しよう
本日の記事について
現在、フィヨルドブートキャンプでプログラミングを学習中です。本記事では、スクールでの課題を進める上での気づきなどをまとめています。
まずアプリ作成の流れなどを振り返ります。
- 『Railsの教科書』内で紹介されていたBookアプリを作成します
- 日本語に対応するためにgem
i18nを実装 - ページネーション機能をgem
kaminariで実装 - ログイン・ログアウト機能をgem
deviseとdevise-i18nで実装 - GitHubによるログイン機能をgem
OmniAuthで実装 - ActiveStorageによるプロフィール画像のアップロード機能実装
- コメント機能を実装してみよう!←今日はここです!
現状では、以下の3つのモデルが存在しています。
- 書籍の登録情報を記録する
Bookモデル - 日報のデータを記録する
Reportモデル - ユーザー情報を記録する
Userモデル
reportsとそのCRUD機能については、booksとほぼ同様ですので、作成手順などを記事では紹介していません。
コメント機能実装の目的と手順
実装の目的は以下の2つです。
- コメント機能を
booksとreportsに追加する - ポリモーフィック関連付けを用いて、
booksおよびreportsにつけたコメントを共通のコードで動かす
実装のざっくりした手順は以下となります。
- commentsのモデル(
Comment)とcontroller(comments_controller.rb)を生成する - モデル生成時に、t.referenceの記述を入れてmigrateする
- models/のファイルやconfig/routes.rbにルーティングを記述する
- viewsとcontrollerの処理などを独自で記述する
手順の詳解
1. commentsのモデル(Comment)とcontroller(comments_controller.rb)を生成する
まず、Commentのモデル作りましょう。
rails g model Comment title:string body:text
class CreateComments < ActiveRecord::Migration[5.2] def change create_table :comments do |t| t.string :title, null: false t.text :body, null:false t.references :commentable, polymorphic: true, index: true t.timestamps end end end
新たにモデルを作成した際の通常のマイグレーションスクリプトとは少しだけ内容が異なっているのがお分かり頂けますでしょうか。
実は、t.references :commentable, polymorphic: true, index: trueという記述を追記しています。
こちらは何を意味しているのでしょうね?この内容を理解するために、まずポリモーフィックについて確認する必要があります。
ポリモーフィック関連付けとは
少し触れましたが、本課題では、booksおよびreportsにつけたコメントを共通のコードで動かすことが条件となっています。
よく考えるとすごく難しそうですよね。何故なら、CommentはBookにもReportにも属していることになるからです。どのように関連付けしたら良いのか不明ですね。
このような場合に役立つのがポリモーフィック関連付けです。
こちらを用いると、ある1つのモデル(Comment)が他の複数のモデル(BookとReport)に属していることを、1つの関連付けだけで表現することが可能になります。

# 記載方法1 class CreateComments < ActiveRecord::Migration[5.2] def change create_table :comments do |t| t.string :title, null: false t.text :body, null:false t.integer :commentable_id t.string :commentable_type t.timestamps end add_index :comments, [:commentable_type, :commentable_id] end end
上記のER図の通り、commentable_idとcommentable_typeは外部参照キーとなります。必ずカラムの型を宣言するのを忘れないようにしましょう。
そして、app/models/の各ファイルに以下を記述します。
2. モデル生成時に、t.referenceの記述を入れてmigrateする
3. models/のファイルやconfig/routes.rbにルーティングを記述する
# app/models/comment.rb class Comment < ApplicationRecord belongs_to :commentable, polymorphic: true end # app/models/book.rb class Book < ApplicationRecord has_many :comments, as: :commentable end # app/models/report.rb class Report < ApplicationRecord has_many :comments, as: :commentable end
このように宣言してあげることにより、commentableで関連付けが可能になります。
ルーティングの設定も忘れないようにしましょう。
# config/routes.rb resources :books do resources :comments, only: [:show, :create, :destroy, :edit, :update] end resources :reports do resources :comments, only: [:show, :create, :destroy, :edit, :update] end # only: [:show, :create, :destroy, :edit, :update]は適宜
こうすることで、 下記のようにパスを返すメソッドが設定されます。
例: report_comment_path(パスは/reports/:report_id/comments/:id)
関連付けできているか見てみよう!
注意:この画面は一通り実装が終わった後の画面です。

rails console(rails c)でテーブルの情報を実際に確認しましょう!
$ comment = Comment.find(1)

外部キーのcommentable_typeに親モデルのクラスであるBookが入っていることが確認できますね。また、commentable_id にはBookのidが入っています。
では、models/以下のファイルやマイグレーションスクリプトに記載したcommentableで親モデルの情報を取得しましょう。
$ comment.commentable

コメントに紐づいたBookモデルのインスタンスが確認できましたね!関連付け、成功です。
ちなみに、t.referencesを用いるとマイグレーションスクリプトの記述内容を減らすことができます。簡略化した記載方法ですので、記載方法1と共に参考にしてください。
# 記載方法2 class CreateComments < ActiveRecord::Migration[5.2] def change create_table :comments do |t| t.string :title, null: false t.text :body, null:false t.references :commentable, polymorphic: true, index: true t.timestamps end end end
buildの利用について
ここまでは主に関連付けの方法について確認しました。ここからは、処理を記述する際に悩みやすいポイントについて整理します。
まず、日報(report)に紐づいたコメント(comment)を新規作成する処理について考えましょう。
それぞれのモデルである、インスタンス変数@reportと@commentを利用します。
コントローラの処理内で@commentを親モデルの@reportに紐づけるにはどうしたらよいのでしょうか。
このような場合はbuildを用いると比較的楽に実装できます。
# comments_controller.rb @report = Report.find(params[:report_id]) @comment = @report.comments.build
上記のように記述してあげると、外部参照キーなどの設定をしなくても自動で紐づきが可能となります。
あとは、フォームを記述すればOKです。
# show.html.erb <%= form_with(model: [@report,@comment], local: true)do |f| %> <%= f.label :content %> <%= f.text_area :content %> <%= f.submit "コメントする" %> <% end %>
処理の詳細については、割愛いたします。
最後に
いかがでしたでしょうか。関連付け、とても奥が深いですね!
参考文献:
Railsの学習(DBとモデル編)
DBとモデルについて
DBとは
DBとは、追加や検索などが容易にできるよう整理されたデータの集まりのことを指します。DBは通常、複数のテーブルの集合で構成されています。
各テーブルの構成要素
下記のテーブルのように、2種類の要素で構成されています。
- 1つのデータを表すレコード(
1,りんご、250、2019/05/29) - データの内容を表すカラム(
id、商品名、価格、発売日)
| id | 商品名 | 価格 | 発売日 |
|---|---|---|---|
| 1 | りんご | 250 | 2019/05/29 |
| 2 | バナナ | 180 | 2019/05/28 |
DBには様々な種類が存在しますが、中でも複数の関係を基本的なデータ型とするリレーショナルデータベース(RDBMS)が普及しています。
Railsのコンポーネントについて
モデルの話に入る前に、Railsの機能と構成について少し取り上げます。
Railsにおける基本のコンポーネント(Rubyで記述されたライブラリ)は、以下の3つです。
Active RecordAction ViewAction Controller
それぞれ、モデル、ビュー、コントローラに対応しており、覚えておくと良いですね!
また、その他にも、電子メール送信を扱うAction Mailerや画像のアップロード作業を扱うActive Storageなどが様々なパッケージが存在します。
モデルとは
ActiveRecordActionViewActionController
この3つのうち、Model(モデル)のgemパッケージに該当するのがActiveRecordです。ActiveRecordはDBとのやり取りを行うGemパッケージです。
MVCフレームワークにおけるModel(モデル)とは、DBとのやり取りを行うクラスのことを指します。
モデルクラスのインスタンスは、1つのレコードを表すオブジェクトとなります。
| id | name | price | date |
|---|---|---|---|
| 1 | りんご | 250 | 2019/05/29 |
| 2 | バナナ | 180 | 2019/05/28 |
例えば、上記のテーブルの場合を考えましょう。
fruit = Fruit.find(2) #2番目のレコードを取得 name = fruit.name fruit.price = 300
まず、findメソッドにidの番号を渡すことによって、fruitテーブルの2番目のレコードを取り出しました。
その後は、変数名.カラムと同名のメソッドのように記述して各カラムの値を取り出して変数に格納しています。
このように、メソッドによる呼び出しがSQL文に自動で変換されてDBMSに送信されているため、RailsではSQL文を知らなくても容易に値を取得することが可能です。
レコードの検索メソッドについて
テーブルのレコードを検索する際に必要なメソッドについて確認しましょう。
- findメソッド
- find_byメソッド
- whereメソッド
findメソッド
user = User.find(2)
findメソッドにidの値を指定すると、その値を持つレコード(モデルオブジェクト)の取得が可能です。
DBの主キーはデフォルトがidですが、念の為クラスメソッドのidsを使って主キーのカラムを確認してから検索しましょう。

find_byメソッド
user = User.find_by(name: "Yoko")
findメソッドと異なり、特定のカラムを使ってレコードを検索するメソッドがfind_byです。
最初に条件に一致したもののみをデータとして返します。
findメソッドとfind_byメソッドはファインダーメソッドと呼ばれます。
whereメソッド
SQLのwhere句に該当するのがwhereメソッドです。こちらは、検索条件を細かく指定できるクエリーメソッドの一種です。
クエリーメソッドを使用してあげると検索条件を理解しやすいコードで記述できる他、複数のレコードを取得できます。
users = User.where("age < 50")
find_byメソッドと似ているようですが、クエリーメソッドはActiveRecord::Relationクラスの配列に似たオブジェクトを返します。
また、上記のように検索条件を文字列で指定することが可能です。
上記の場合、年齢が50歳未満の複数のデータが格納されたオブジェクトを返すため、テンプレート上で下記のような表示が可能です。
<% if @users %> <% @users.each do |user| %> <%= user.name %> <% end %> <% end %>
クエリーメソッドの応用
SQL文を記載するように、クエリーメソッド同士の組み合わせやファインダーメソッドとの組み合わせも可能です。
# クエリーメソッド同士の組み合わせ users = User.where(name: "Yoko").where("age < 50") members = Member.where(sex: 2).order("number") # ファインダーメソッドとの組み合わせ user = User.where(sex: 2). order(:age).first
結果をソートしたい場合、orderメソッドを使用するとnumberカラムの昇順で結果を取り出すことが可能です。
また、ファインダーメソッドのfirstメソッドやlastメソッドと組み合わせると、最初に一致するレコードを1つ返します。
firstメソッドやlastメソッドを使用する場合は、結果が安定するように、orderメソッドでソート順にしてあげると良いです。
最後に
今回はデータの検索を中心に取り上げました。
自動化テストの基本
自動テストについて
前回の記事まで、gemを使ってBookアプリに様々な機能を実装しました。本記事より自動化テストを扱います。
まずは、その中でも代表的な手法であるTDD(テスト駆動開発)について学習しましょう!
TDDとテストの定義
TDDとはTest Driven Developmentの略で、日本語では「テスト駆動開発」と呼ばれています。Kent Beck氏によって提唱された概念です。
こちらの書籍も非常に有名ですよね。
テスト駆動開発(以下、TDDと略)の「テスト」ってそもそも何をテストするのでしょうね。テストの観点は大きく分けると以下の2種類に分けられます。
- 機能要件
- 非機能要件
上記の内、機能要件を扱うのがTDDにおけるテストのことでDeveloper Testingと呼びます。文字通り、開発者によるテストのことを指します。
一方、堅牢性や情報セキュリティといった仕様や機能以外の非機能要件をテストするのは品質保証などを扱うQAテストです。一般的にテストというと、こちらを連想するかもしれませんね。
TDDとは、機能の期待通りの動作を担保するために、まずテストコードを書いて開発を進める手法を指します。テストファーストという概念自体が個人的にはすごく新鮮です。
TDDのサイクル
TDDは以下の3プロセスから構成されています。
- Red
- Green
- Refactor
それぞれを確認しましょう。
1. Red
機能要件を元に、メソッド内容IFと出力結果を記載した失敗するテストを書きます。
2. Green
失敗するテストを元に実装を進め、テストを成功させる最低限のコードを書きます。
3. Refactor
完成したテストが失敗しないようにコードの内容を変更、必要に応じてテストを追加します。
コードの変更がある場合は再度失敗するテストを書き、テストに合わせてコードを実装しサイクルを回していきます。
上記の3ステップを素早く小さく繰り返すことできれいな動くコードを目指します。
テストの種類
Developer Testingもその目的によって何種類かに分かれます。
単体テストとは、1クラスや1メソッドを対象とした最小単位のテストのことで、機能が意図した通りに正しく動作するかどうかを検証します。 テストの粒度が細かく、バグが発生した箇所を細かく分析することができるなどのメリットがあります。
より対象を広げ,複数のメソッドやモジュール間の連携をテストするのが機能テストです。こちらはテストの粒度が大きめです。
一般的にバグ発見などのメリットがあることや粒度が大きいテストはメンテナンスが煩雑になることなどから、単体テスト(ユニットテスト)を優先して行う傾向があるそうです。
先程取り上げたTDDは、ユニットテストとリファクタリングを両輪とした非常に小さくて狭いフィードバックサイクルを回す手法と言えますね。
Rubyにおけるテスティングフレームワーク
Railsを扱うため、ここからはRuby標準のテスティングフレームワークについて確認しましょう。テストにおけるフレームワークは以下の3種類です。
- Minitest
- RSpec
- test-unit
RSpec以外はRubyのインストール時に同梱されるのでgemのインストールは不要です。
また、Minitestとtest-unitについてはテストコードも似ており、RSpecは独自のDSLを用いるため記法が異なっているという特徴があります。
何故3種類も存在しているかというと、Rubyのバージョン毎に標準のフレームワークが変わっていたという複雑な(?)歴史があったためです。
Minitestとtest-unitについては現在両方とも標準として使用可能ですので、両方理解できているといいですね。
今回はこの中でもtest-unitに焦点を当てます!
test-unitについて
RubyにはTEST::Unitというクラスライブラリが存在し、こちらを用いて単体テスト(ユニットテスト)を行います。
検証メソッドはいたってシンプル。数種類存在しますが、assert_equal b(期待値), a(実際の値)(aがbと等しければパスする)などが使えれば問題なさそうです。
では、コードを実際に見てみましょう!
以下は、『プロを目指す人のためのRuby入門』第3章の内容を参考にしたプログラムです。
# テストコード require 'test/unit' require './lib/fizz_buzz' class FizzBuzzTest < Test::Unit::TestCase def test_fizz_buzz assert_equal '1', fizz_buzz(1) assert_equal '2', fizz_buzz(2) assert_equal 'Fizz', fizz_buzz(3) end end
まず、Test::Unit::TestCaseを継承したクラス(この場合FizzBuzzTest)を用意します。
そのクラス内でtest_で始まるメソッド(この場合はtest_fizz_buzz)を定義するとそのメソッドがテストの実施対象になります。
もちろんテストコードとは別に、ファイルを分けてfizz_buzzというメソッドを記述しています。
# fizz_buzz.rb def fizz_buzz(n) if n % 21 == 0 'Fizz Buzz' elsif n % 3 == 0 'Fizz' elsif n % 7 == 0 'Buzz' else n.to_s end end
実行方法は、Ruby ファイル名でOKです。比較的簡単にテストが実施できますね。
実行結果の画面

最後に
いかがでしたでしょうか。test-unitは素のRubyで比較的簡単にテストが実施できるので便利ですね。 次回よりRSpecを中心に記事を書く予定です。
参考文献:
www.slideshare.net
ActiveStorage
ActiveStorageとは
Rails5.2より同梱されているファイル管理のgemです。
クラウドストレージサービスなどへファイルをアップロードして、 DB上でActiveRecordモデルへ紐づけることなどが比較的簡単にできます。
本記事では、BookアプリにActiveStorageを実装してプロフィール画像をアップロードする機能を追加します。
本記事の前提
内容に入る前に、以前の記事と同様にまずアプリ作成の流れなどを振り返ります。
- 『Railsの教科書』内で紹介されていたBookアプリを作成します
- 日本語に対応するためにgem
i18nを実装 - ページネーション機能をgem
kaminariで実装 - ログイン・ログアウト機能をgem
deviseとdevise-i18nで実装 - GitHubによるログイン機能をgem
OmniAuthで実装 - ActiveStorageによるプロフィール画像のアップロード機能実装←今日はここです!
上記の通り、本の登録機能やユーザーの認証機能は実装済みです。
ActiveStorageの導入プロセス
プロセスはいたってシンプルです。
- imagemagickのインストール
- ActiveStorageの準備
- ファイル管理の場所を設定
- Userモデルに画像を添付できるようファイルに追記
- テンプレート修正
内容を確認していきましょう!
1. imagemagickのインストール
Railsガイドにも記載がありますが、variantというメソッドを使用するとアップロードする画像のサイズなどを変換することが可能です。
variantを有効にするには、以下の2つが必須。
- imagemagickをシステム上でインストール済みであること
- gemのmini_magickをロードすること
$ brew install imagemagick
Homebrewを使ってimagemagickをインストールしたら、今度はGemfileにmini_magickというgemも追記しましょう。
# Gemfile gem 'mini_magick'
bundle install実行で準備万端です。
2. ActiveStorageの準備
ここからがActiveStorageの準備作業です。gemのインストールは不要なので、その代わりに下記コマンドを実行。
$ rails active_storage:install
マイグレーションファイルが出力されるので、DBに反映するためrails db:migrateを忘れずに。
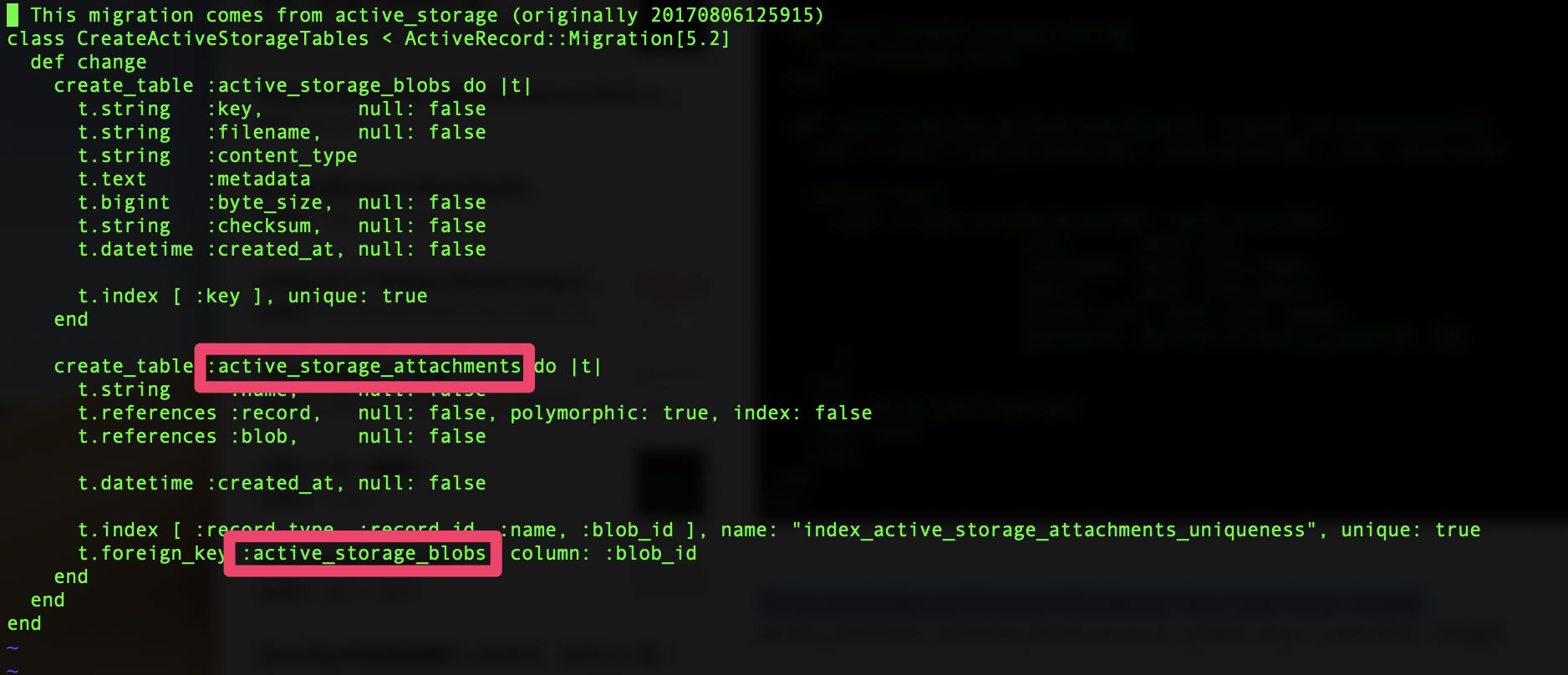
ActiveStorageが利用するテーブル(active_storage_blobsとactive_storage_attachments)を作成。
ActiveStorage::Attachmentはアプリ内のモデル(この場合Userモデル)とActiveStorage::Blobを結びつける中間テーブルのこと。
ActiveStorage::Blobは、添付された画像ファイルに対応するモデルのことです。ファイルの実体(ファイル名やメタデータなど)をDB外で管理することを前提にしています。
3. ファイル管理の場所を設定
添付したファイルを管理する場所の設定を確認しましょう。
config/environments/development.rb内のconfig.active_storage.serviceにファイルを管理する場所を付与します。下記を追記しましょう。
config.active_storage.service = :local
上記の場合、管理場所をlocalに設定しています。では、ファイルの管理場所が定義されているconfig/storage.ymlの内容を確認します。
# config/storage.yml test: service: Disk root: <%= Rails.root.join("tmp/storage") %> local: service: Disk root: <%= Rails.root.join("storage") %> # Use rails credentials:edit to set the AWS secrets (as aws:access_key_id|secret_access_key) # amazon: # service: S3 # access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> # secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> # region: us-east-1 # bucket: your_own_bucket
localはローカル環境(Railsアプリのディレクトリ配下のstorageディレクトリのこと)にファイルを格納する設定のことです。
ちなみに、デフォルトで用意されているのがlocalの設定です。AWSなどのサービスを利用しない場合はこのままでOKです。
クラウドを利用して画像をアップロードする場合は、config.active_storage.service = :amazonなど記述を適宜変更する必要があります。
4. Userモデルに画像を添付できるようファイルに追記
まず、app/models/user.rbに追記して、Userモデルにimageという画像を扱う属性を付与します。
has_one_attachedのメソッドを用いることで、1つのuserに1つの画像を紐づけることとその画像をUserモデルからimageと呼ぶことを指定することが可能になります。属性名はavatarなど別の名称でもOKです。
# app/models/user.rb class User < ApplicationRecord 省略 has_one_attached :image 省略 end
そして、アップロードしたファイル情報が、Strong Parametersによって無視されないように:imageを追加しましょう!
Strong Parametersについては以前この記事で取り上げました。
#app/controllers/application_controller.rb devise_parameter_sanitizer.permit(:sign_up, keys: [:username, :image])
私はプロフィールの編集画面からも画像を変更できるよう設定したかったため、下記の記述も追記しました。
#app/controllers/application_controller.rb devise_parameter_sanitizer.permit(:account_update, keys: [:username, :image])
5. テンプレート修正
こちらは各自テンプレートにimageのフィールドなどを足しましょう。また、必要に応じてロケールファイルにも単語を追加してくださいね。
<div>
<%= f.label :image %>
<%= f.file_field :image %>
</div>
以上で設定終了です!
設定完了画面
画像アップロード

画像編集

編集画面

編集完了

最後に
いかがだったでしょうか。ActiveStorageはdbにカラムなどを追加しなくても画像が管理できるので便利ですよね! 本記事は以上となります。
参考文献:
OAuthについて
OAuthについて
OAuthとは、第三者となるアプリケーションに対して安全にアクセス権限を提供するためのプロトコルのことです。OAuthを利用すると、例えばTwitterやFacebookなどのSNSからログインすることが可能となります。
本記事ではgemのOmniAuthを利用してGitHub認証をBookアプリに実装します。
本記事の前提
内容に入る前に、まずアプリ作成の流れなどを振り返ります。
- 『Railsの教科書』内で紹介されていたBookアプリを作成
- 日本語に対応するためにgem
i18nを実装 - ページネーション機能をgem
kaminariで実装 - ログイン・ログアウト機能をgem
deviseとdevise-i18nで実装 - GitHubによるログイン機能をgem
OmniAuthで実装 ←今日はここです! - ActiveStorageによるプロフィール画像のアップロード機能実装
deviseを利用することで、メール認証など一旦ユーザー認証の機能は追加済みです。
DBにはBookとUserのテーブルが存在しており、モデルの作成後、Userテーブルにカラムの追加はしておりません。

OmniAuth導入にあたっての補足
基本的にこちらの記事を参考にして進めました。 こちらの内容通りに進めれば問題なく実装できるかと思います。
大枠として、プロセスは以下のようなイメージです。
- GitHub連携の準備のため、GitHub上で"Client ID"と"Client Secret"の取得
OmniAuthのインストール- DBテーブルへのカラムの追加
- app/models/user.rbへのメソッド追加
dotenv-railsをインストールし、.envファイルを作成して"Client ID"と"Client Secret"を記述- コールバック処理のコントローラを作成する
- config/routes.rbとconfig/initializers/devise.rbの修正
- viewsファイルの修正
一部補足事項がありますのでこちらの記事で紹介いたします。
3. DBテーブルへのカラムの追加
deviseとomniauthを同時にインストールする場合などは、記事通りに実行すれば問題ありません。 私は既ににdeviseのインストールと実装を済ませていたので、必要なカラムを追加してマイグレーションファイルを確認する必要がありました。
OmniAuth利用に必要なカラムは以下の2つ。
uidとprovider(この場合はGitHubですね!)
uidとproviderについてはDBのデータを検索するメソッドで必要になるため、テーブルに存在していない場合追加してあげましょう。
# uidとproviderの追加 $ rails g migration AddUidToUser uid:integer provider:string
また、必須ではないのでがログイン画面でユーザー名を表示したい場合などに必要なusernameもしくはnameを登録する場合があります。これはoAuthというよりdeviseのトピックになりますね。
deviseを利用すると、認証に必要なデータとしてデフォルトでemailとパスワードが利用できますが、それ以外のカラム(代表的なのがusernameです)をDBに追加して認証に利用する場合、前回の記事でも紹介したstrong parametersの仕組みを考慮する必要があります。
# usernameの追加 $ rails g migration AddUserameToUser username:string:uniq #ユニークにするために:uniqを使用 $ rails db:migrate
application_controller.rbのbeforeフィルターに別途処理を記述しましょう。以下の記述を忘れるとstrong parametersによりエラーが発生します。
# application_controller.rb class ApplicationController < ActionController::Base before_action :configure_permitted_parameters, if: :devise_controller? protected def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [:username]) end end
また、usernameを追加した場合viewsについてもカスタマイズする必要があります。
4. app/models/user.rbへのメソッド追加
Modelに様々なメソッドを追加するのですが、特に以下の処理は重要です。
uidとproviderによりDBを検索して、値が存在しない場合は、新規でユーザーインスタンスを作成するというメソッドですね。
# app/models/user.rb def self.find_for_github_oauth(auth, signed_in_resource=nil) user = User.find_by(provider: auth.provider, uid: auth.uid) unless user user = User.create(provider: auth.provider, uid: auth.uid, username: auth.info.name, email: User.dummy_email(auth), password: Devise.friendly_token[0, 20] ) end user.skip_confirmation! user.save user 省略
こちらのメソッドは下記のコールバックの処理で使用されます。ユーザーが存在する場合としない場合とで条件分岐させてログイン認証の処理を分けていますね。
引数のauthとして渡されるのがrequest.env['omniauth.auth']です。
# app/controllers/users/omniauth_callbacks_controller.rb class Users::OmniauthCallbacksController < Devise::OmniauthCallbacksController def github @user = User.find_for_github_oauth(request.env["omniauth.auth"], current_user) if @user.persisted? sign_in_and_redirect @user, :event => :authentication set_flash_message(:notice, :success, :kind => "Github") if is_navigational_format?
request.env['omniauth.auth']というリクエストパラメータには、OmniAuthによってHashのデータ構造に似たOmniAuth::AuthHashというクラスのオブジェクトが格納されています。oAuthによるこれらのデータを取得して、検索を行うのですね。
5. dotenv-railsをインストールし、.envファイルを作成して"Client ID"と"Client Secret"を記述
.envのファイルに環境変数としてGitHubのAPI keyを登録します。環境変数として認識させるためにdotenv-railsのインストールをお忘れずに。
.envを.gitignoreに置くことでGitHub上へのファイルのコミットを防ぎます。
以上となります。
OmniAuth実装上の注意点
-------deviseでメール認証を実装された方に向けた内容になります-------
実はGitHubの認証が上手くいっても、メール認証の設定によりログインができない場合があるのです。
こちらの記事のコメント欄にも同様の事象を経験されている方がいらっしゃいます。
メール認証のアラートが飛ぶ場合は、GitHub認証時にメール認証を省略するための記述が別途必要なのです。
それが、obj.skip_confirmation!です。
# app/models/user.rb user = User.create(:username => data.name, 省略 ) user.skip_confirmation! #user.saveの前に処理を記述 user.save
上記の記述をすることで、GitHubによるログインを実行した後にメール認証のアラートが飛ぶことはないはずです。
また処理を分けているので、メール認証も引き続き実行可能です。
ログイン後の画面
GitHub認証後の遷移

メール認証後の遷移

参考文献
最後に
いかがでしたでしょうか。個人的には、OmniAuthの導入そのものより、username追加時のdeviseの処理などが難しく感じました。
次回はActiveStorageについてです!